Basic Machine Learning Algorithms: A Comprehensive Guide

Introduction:
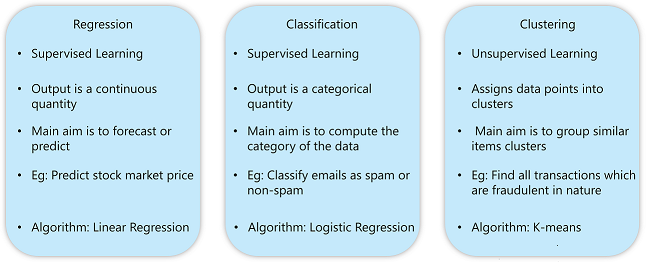
Machine learning is all about creating models that can predict outcomes or find patterns in data. Understanding the basic algorithms used in ML is a critical step for beginners. In this blog, we will explore three fundamental types of machine learning algorithms: Regression, Classification, and Clustering. These algorithms form the building blocks of most ML applications, and you will learn how they work and how to implement them in Python.

Quick Comparison (Very Important)
| Algorithm Type | Predicts | Data Type | Example |
|---|---|---|---|
| Regression | Numbers | Labeled | Salary prediction |
| Classification | Categories | Labeled | Spam detection |
| Clustering | Groups | Unlabeled | Customer segmentation |
For example:
If you are building a college project:
-
Predict marks → Regression
-
Predict pass/fail → Classification
-
Group students by performance → Clustering
1. Linear Regression: Predicting Continuous Values
What is Linear Regression?
Linear regression is a simple algorithm used to predict a continuous outcome (dependent variable) based on one or more input variables (independent variables). It assumes a linear relationship between the inputs and the output, trying to fit a straight line that best represents the data points.
- Key Concept: The algorithm calculates the best-fitting line by minimizing the sum of squared differences between the observed values and predicted values.
- Use Case: Predicting housing prices based on features like size, location, and number of rooms.
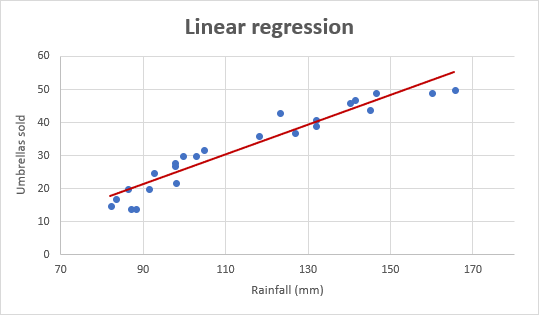
How Linear Regression Works:
- Simple Linear Regression: Involves one independent variable, and the model fits a straight line (y = mx + b) to the data.
- Multiple Linear Regression: Involves more than one input variable, so the equation expands to y = b₀ + b₁x₁ + b₂x₂ + … + bnxn.
Python Implementation:
from sklearn.linear_model import LinearRegression
import numpy as np
X = np.array([[1], [2], [3], [4], [5]]) # Independent variable (Years)
y = np.array([30, 35, 50, 60, 70]) # Dependent variable (Salary)
# Create and fit the model
model = LinearRegression()
model.fit(X, y)
# Predict salary for 6 years of experience
prediction = model.predict([[6]])
print(f"Predicted salary: {prediction}")
Conclusion:
Linear regression is a simple but powerful algorithm for predicting continuous values. It’s widely used in finance, economics, and even marketing to model relationships between variables.
_________________________________________________________________________
2. Classification Algorithms: Predicting Categories
What is Classification?
Classification algorithms predict categorical outcomes, such as "yes" or "no," "spam" or "not spam." These algorithms work by finding decision boundaries that best separate different classes in your data.
Logistic Regression: Binary Classification
Logistic regression is used when the dependent variable is binary (i.e., it has only two possible outcomes). Despite its name, logistic regression is a classification algorithm, not a regression one. Instead of predicting a continuous value, it predicts the probability of a certain class (usually between 0 and 1).
- Key Concept: Logistic regression applies the sigmoid function to the output of a linear equation, converting it into a probability between 0 and 1.
- Use Case: Predicting whether an email is spam or not, based on features like word frequency.
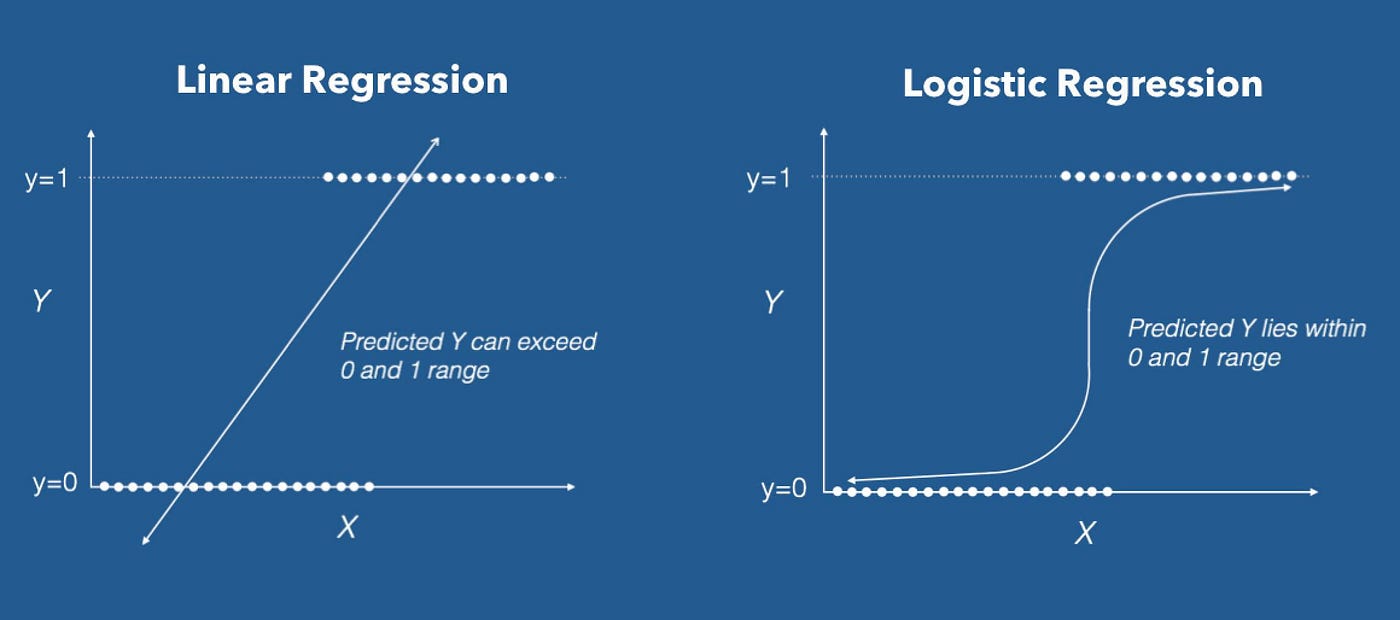
How Logistic Regression Works:
- The logistic function outputs probabilities, which are then thresholded at 0.5 to assign a class (0 or 1)
Decision Trees: A Visual Approach to Classification
Decision trees classify data by repeatedly splitting it into subsets based on feature values, forming a tree-like structure. Each decision is represented as a node, and the final decision (classification) is at the leaf node.
- Key Concept: Decision trees choose splits based on criteria like Gini Impurity or Information Gain to maximize the separation between classes.
- Use Case: Classifying customers into different segments based on features like age, income, and purchase history.
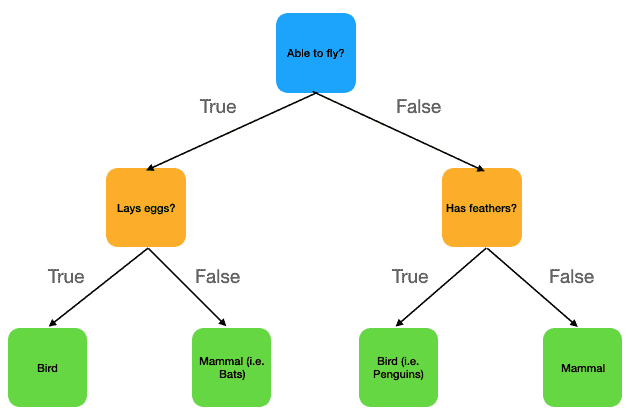
How Decision Trees Work:
- The algorithm splits the data at each node by selecting the feature that provides the most significant separation between classes.
K-Nearest Neighbors (KNN): Classify by Proximity
K-Nearest Neighbors (KNN) is a simple, yet effective, algorithm that classifies data points based on the majority class among the k nearest neighbors.
- Key Concept: KNN assigns a class to a new data point by finding its nearest neighbors and choosing the most frequent class among them.
- Use Case: Classifying if a flower is a specific species based on features like petal length and width.
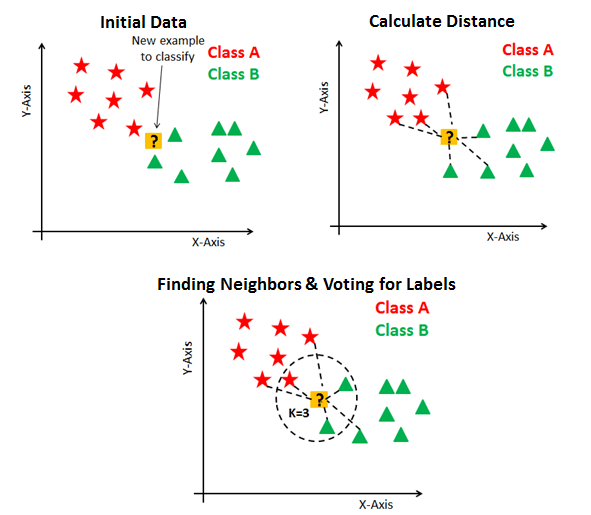
How KNN Works:
- It calculates the Euclidean distance between the test data and the training data points to find the k closest neighbors.
from sklearn.neighbors import KNeighborsClassifier
# Sample data: Features (Height, Weight) and target class (Gender: 1 = Male, 0 = Female)
X = [[170, 70], [160, 60], [180, 80], [155, 55]]
y = [1, 0, 1, 0]
# Create and fit the model
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X, y)
# Predict if a person with height 165 cm and weight 65 kg is male or female
prediction = model.predict([[165, 65]])
print(f"Predicted gender: {prediction}")
3. Clustering Algorithms: Grouping Data Without Labels
What is Clustering?
Clustering is an unsupervised learning algorithm that groups data points into clusters based on their similarities. Unlike classification, clustering doesn't require labeled data.
K-Means Clustering: Partitioning Data into Clusters
K-Means is one of the simplest clustering algorithms. It aims to partition the dataset into k distinct clusters by minimizing the variance within each cluster.
- Key Concept: K-Means assigns each data point to the nearest cluster by minimizing the squared Euclidean distance between the points and the cluster center.
- Use Case: Segmenting customers into distinct groups based on their purchasing habits.
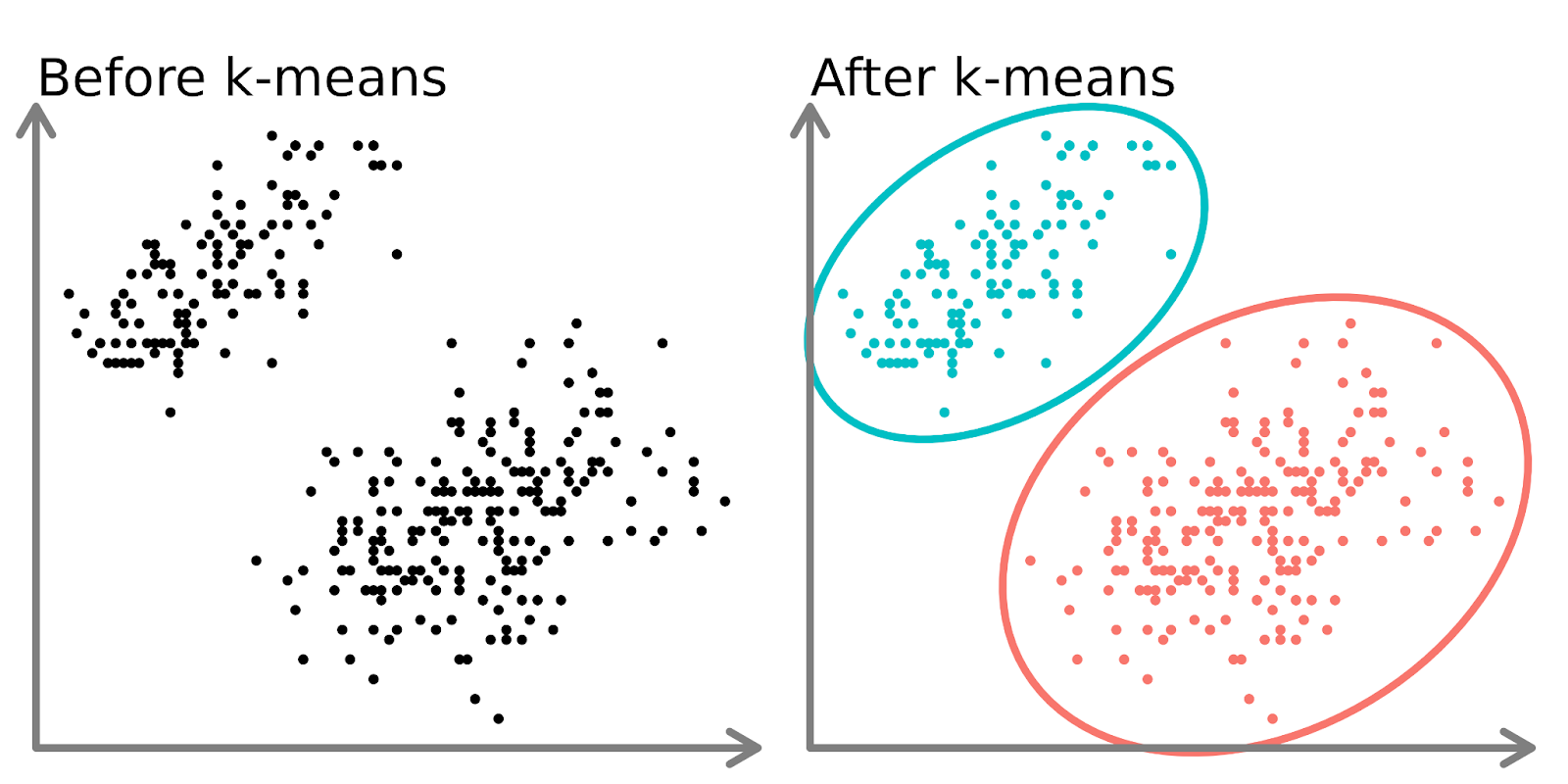
How K-Means Works:
- Randomly initialize k cluster centroids.
- Assign each data point to the nearest centroid.
- Recalculate the centroids and repeat until convergence.
Hierarchical Clustering: Grouping in Nested Clusters
Hierarchical clustering builds a hierarchy of clusters by either merging smaller clusters into larger ones or splitting larger clusters into smaller ones. It results in a dendrogram, which is a tree-like structure that shows the relationship between clusters.
- Key Concept: The process continues until all data points are in a single cluster (agglomerative) or all points are individual clusters (divisive).
- Use Case: Organizing data in hierarchical structures like taxonomies or social networks.



Comments
Post a Comment