How to Build Your First Machine Learning Model: Step-by-Step Beginner Guide
Building Your First Machine Learning Model: A Beginner’s Guide

Machine learning is transforming industries—from personalized recommendations to fraud detection—and now, you too can be a part of this revolution. Building your first machine learning (ML) model may feel overwhelming at first, but when broken down into a step-by-step process, it becomes both manageable and exciting. In this blog, you'll walk through the complete process of developing a machine learning model using real-world datasets and popular tools like Scikit-learn and Pandas
🧩 Key Aspects of Machine Learning Models
Data Collection:
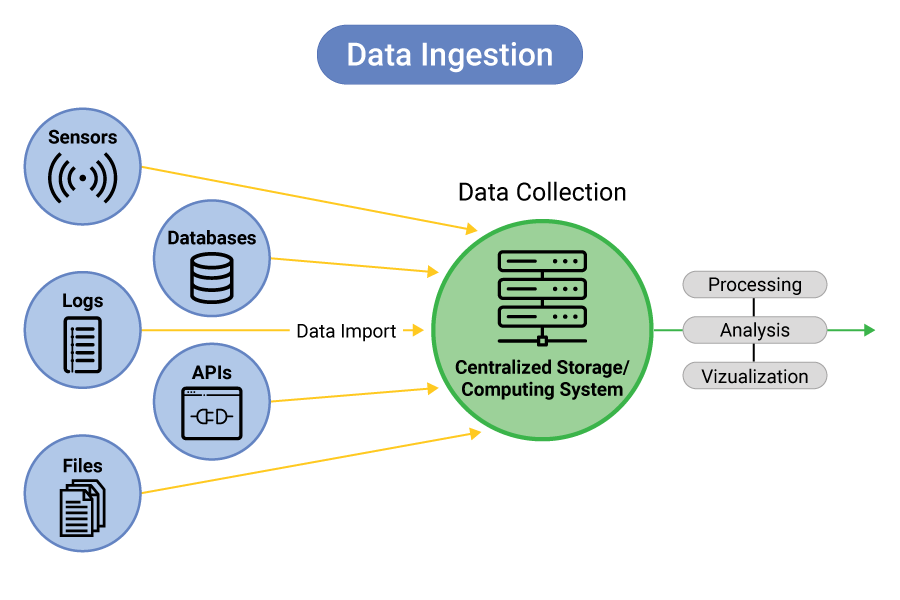
Data is the fuel that powers machine learning models. You can either collect your data through web scraping, APIs, or user input, or download pre-existing datasets from repositories like:
-
Kaggle
-
UCI Machine Learning Repository
-
Google Dataset Search
The quality and relevance of your dataset will significantly influence your model’s performance
-
Data Preprocessing
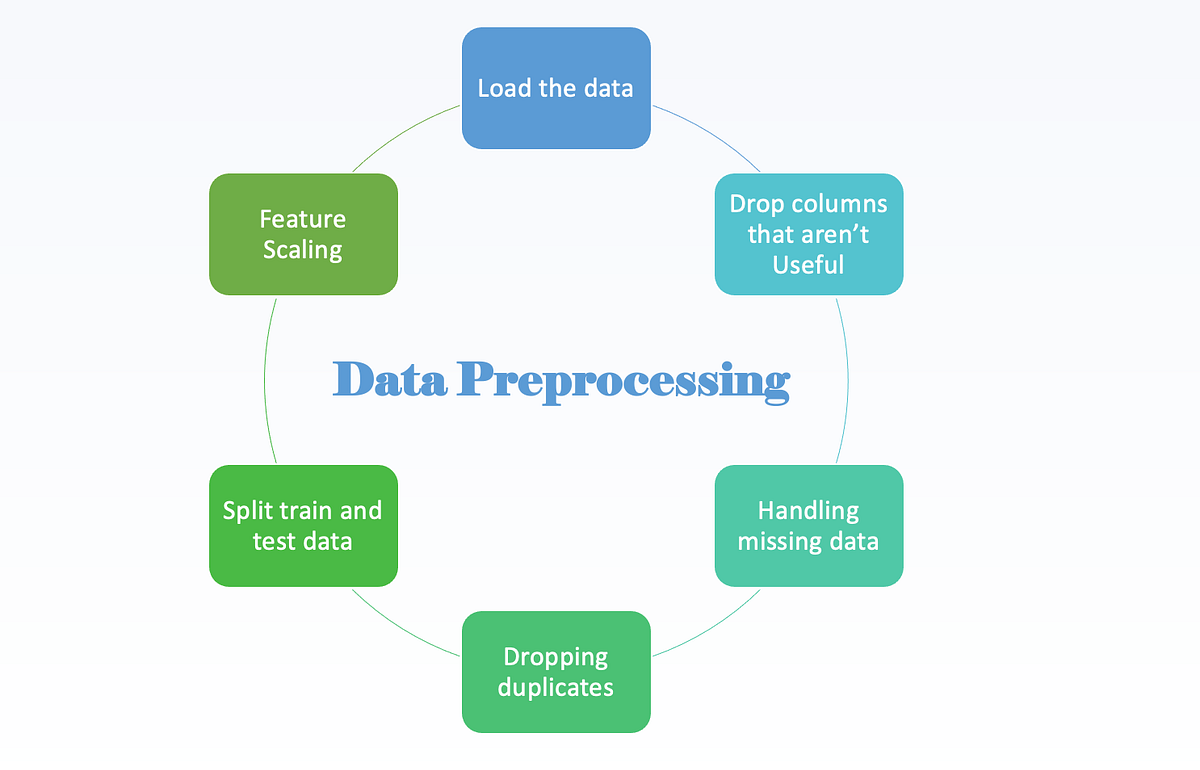
Raw data is rarely ready to use. Preprocessing prepares your data for training by:
-
Handling Missing Data: Fill in or drop missing values.
-
Feature Scaling: Normalize or standardize features for consistency.
-
Feature Encoding: Convert categorical variables into numerical formats using One-Hot Encoding or Label Encoding.
-
Data Splitting: Divide the dataset into training, validation, and testing sets (commonly 80/20 or 70/30 split)
3. Model Selection
Choosing the right algorithm depends on the type of problem you’re solving:
| Algorithm | Type | Example Use Case |
|---|---|---|
| Linear Regression | Regression | Predicting house prices |
| Logistic Regression | Classification | Spam detection |
| Decision Trees | Both | Customer segmentation |
| K-Nearest Neighbors (KNN) | Both | Handwriting recognition |

4. Model Training

5. Model Evaluation

To evaluate your model’s accuracy and reliability, use these key metrics:
-
Accuracy: Proportion of correct predictions.
-
Precision and Recall: Ideal for imbalanced datasets.
-
F1 Score: Balances precision and recall.
-
Confusion Matrix: Displays actual vs. predicted values in a 2x2 matrix.
These metrics help determine whether the model can generalize well to new, unseen data.
These metrics help determine whether the model can generalize well to new, unseen data.Model Optimization:

To improve the model, hyperparameters need tuning. This can be done through methods like grid search or random search to find the best settings for the model.
Model Deployment:

Once satisfied with the model’s performance, the final step is deployment, where the model is made available for real-time predictions, often via an API.
VIDEO LINKS FOR BETTER UNDERSTANDING
Here are some of the best YouTube videos that can guide you through building your first machine-learning model:
"Build Your First Machine Learning Project [Full Beginner Walkthrough]"
This video provides an excellent end-to-end guide on building a machine learning project, covering all the main steps from data collection to model evaluation."Build Your First Machine Learning Model in Python"
This video specifically focuses on using Python and the Scikit-learn library to build your first model, with a step-by-step tutorial for beginners."Build a Machine Learning Model with Python"
Another great video that breaks down how to build a machine learning model from scratch using Python, perfect for understanding the basics.
WANNA TRY YOURSELF HERE SOME HELP FOR YOU
Step-by-Step Process to Build a Machine Learning Model
Step 1: Import Libraries and Load Data
First, import the necessary libraries like Pandas, NumPy, and Scikit-learn. Then load the dataset using Pandas.
import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegression# Load the datasetdata = pd.read_csv("your_dataset.csv")
Step 2: Data Preprocessing
Clean the data by handling missing values, scaling the features, and encoding categorical data.
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
# Handling missing valuesimputer = SimpleImputer(strategy='mean')data_filled = imputer.fit_transform(data)# Feature scalingscaler = StandardScaler()data_scaled = scaler.fit_transform(data_filled)# Encoding categorical featuresencoder = OneHotEncoder()data_encoded = encoder.fit_transform(data_scaled)
Step 3: Split the Dataset
Divide your dataset into training and test sets. Typically, you’ll use 80% of the data for training and 20% for testing.
X = data_encoded[:,:-1] # Featuresy = data_encoded[:,-1] # Target variable
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Step 4: Train the Model
Choose a model and train it using the training data.
# Using a Logistic Regression modelmodel = LogisticRegression()model.fit(X_train, y_train)
Step 5: Evaluate the Model
Evaluate the model on the test set using various metrics.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
y_pred = model.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
# Confusion matrix
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:\n", cm)
# Classification report
print("Classification Report:\n", classification_report(y_test, y_pred))
Step 6: Model Optimization
If necessary, optimize the model using hyperparameter tuning (like Grid Search).
from sklearn.model_selection import GridSearchCV# Hyperparameter tuning using Grid Searchparam_grid = {'C': [0.1, 1, 10], 'solver': ['lbfgs', 'liblinear']}grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5)grid_search.fit(X_train, y_train)# Best parametersprint("Best Parameters:", grid_search.best_params_)
Step 7: Deployment
Once the model is trained and optimized, it’s ready for deployment. You can save the model and integrate it into an application to make predictions in real time.
import joblib# Save the model to a filejoblib.dump(model, 'final_model.pkl')# Load the model for future useloaded_model = joblib.load('final_model.pkl')
Conclusion
Building a machine learning model involves understanding the problem, collecting and preprocessing data, choosing the right algorithm, training the model, evaluating its performance, and optimizing it for better results. This process ensures that your model is effective and ready for real-world applications.


Very well-structured and informative post! The step-by-step breakdown made it easy to follow the ML pipeline, especially for beginners. Thanks for simplifying the process so clearly!
ReplyDeleteThank you! I’m really glad to hear the structure and breakdown helped make the ML pipeline easier to understand—especially for beginners. Appreciate your kind words!
Delete